Definition:-
- LRU stands for ‘least recently used’. It is a computer algorithm used to manage the cache area which stores data in the memory. When a cache becomes full and you need space for new data. Hence you will discard the least recently used items first, things you haven’t used for a while but are in the cache consuming space.
- MRU stands for ‘most recently used’. When you access the data in the block, the associated block will go into the MRU end of the managed list. It is like keeping the type of greeting cards most people liked in the prime visible area for delightful customer experience.
Now let us see the techniques used for data gathering. It mainly depends on the number of time data (or) block accessed by the request & how we manage the data.
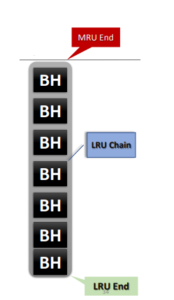
Standard LRU Algorithm (Buffer Cache):-
- Extremely Simple – uses a single linear chain
- Introduced concept of Hot and Cold data is managed at the hot & cold ends of each LRU chain
- On-demand hot data (or) buffers placed at hot ends (MRU chain)
- Not recommended for large-sized tables accessed with FTS (Full Table Scan)
- LRU chain buffer data getting rewritten with FTS buffers
- Flushing entire hot data from cache leading to disk I/O reads on hot data
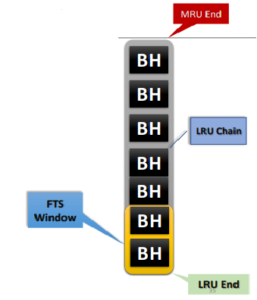
Modified LRU Algorithm (Buffer Cache):-
- Took into account the issue of buffer accessed by entire LRU chain
- Implemented with an additional “window” in the LRU chain only meant for FTS buffers data
- A hidden parameter to control the number of buffers in FTS window (“_small_table_threshold”)
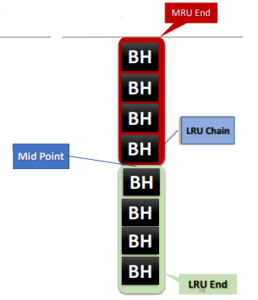
Mid-Point Insertion/Touch Count Algorithm:-
- LRU chain still has a so-called MRU and LRU ends & has a mid-point dividing it
- Midpoint controlled by “_db_percent_hot_default” hidden parameter
- Buffers will be linked to the LRU end when the buffer count larger than “_small_table_threshold” parameter settings. Otherwise, it will be in the MRU end
- Buffer promotion/demotion and eviction is now based on the “touch count” recorded in the buffer header (BH)
- Touch count is incremented with every buffer access after a 3 secs timeout from last access
- With every “touch” to the buffer, touch counter increments & recorded in the cache header
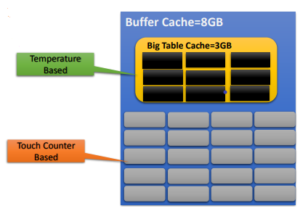
Large Table Caching in 12c using Object Temperature:-
- Entire object can be replaced using “temperature” of the objects
- Configure Big Table Cache within the Buffer Cache DB parameter
- Beneficial for scans of large objects do not fall under default cache
- Useful in specific environments like DWH
- Works along with In-Memory parallel query
About Nimesa
Nimesa is enterprise-class Application-Aware data protection, cost management & copy data management solution for applications running on AWS. It uses native AWS capabilities like EBS snapshots capabilities to automatically protect the environment. It provides simple policy-based lifecycle management of snapshots and clones of EC2 instances.
To know more of how to protect your environment using Nimesa refer to the previous blog